Votre panier est vide!
🔴 Niveau : Avancé | ⏱️ Lecture : 18 min | 🛠️ Mise en œuvre : 4-8 heures
📚 Prérequis
- Connaissances de base de PostgreSQL (installation, requêtes SQL)
- Compréhension des concepts de réplication et de haute disponibilité
- 3 serveurs Linux minimum (4 Go RAM, 2 vCPU chacun)
- Expérience avec la configuration réseau (ports, firewalls)
PostgreSQL est la base de données open-source la plus avancée au monde. Mais en production, une instance unique est un SPOF (Single Point of Failure) inacceptable. Comment mettre en place une vraie haute disponibilité avec failover automatique ? Découvrez l’architecture Patroni + etcd + HAProxy, la référence actuelle.
🤔 Pourquoi PostgreSQL HA est Complexe
Contrairement à ce qu’on pourrait croire, la haute disponibilité de PostgreSQL n’est pas « plug and play ». Plusieurs défis se posent :
Le Problème du Split-Brain
Imaginez ce scénario catastrophe :
- Le réseau entre deux nœuds PostgreSQL se coupe temporairement
- Chaque nœud pense que l’autre est mort
- Les deux se déclarent « Primary » et acceptent des écritures
- Quand le réseau revient → données divergentes, corruption
C’est le split-brain, le cauchemar de tout DBA.
La Solution : Le Consensus Distribué
Pour éviter le split-brain, il faut un arbitre externe qui décide quel nœud est le vrai Primary. C’est le rôle d’etcd (ou Consul, ZooKeeper).
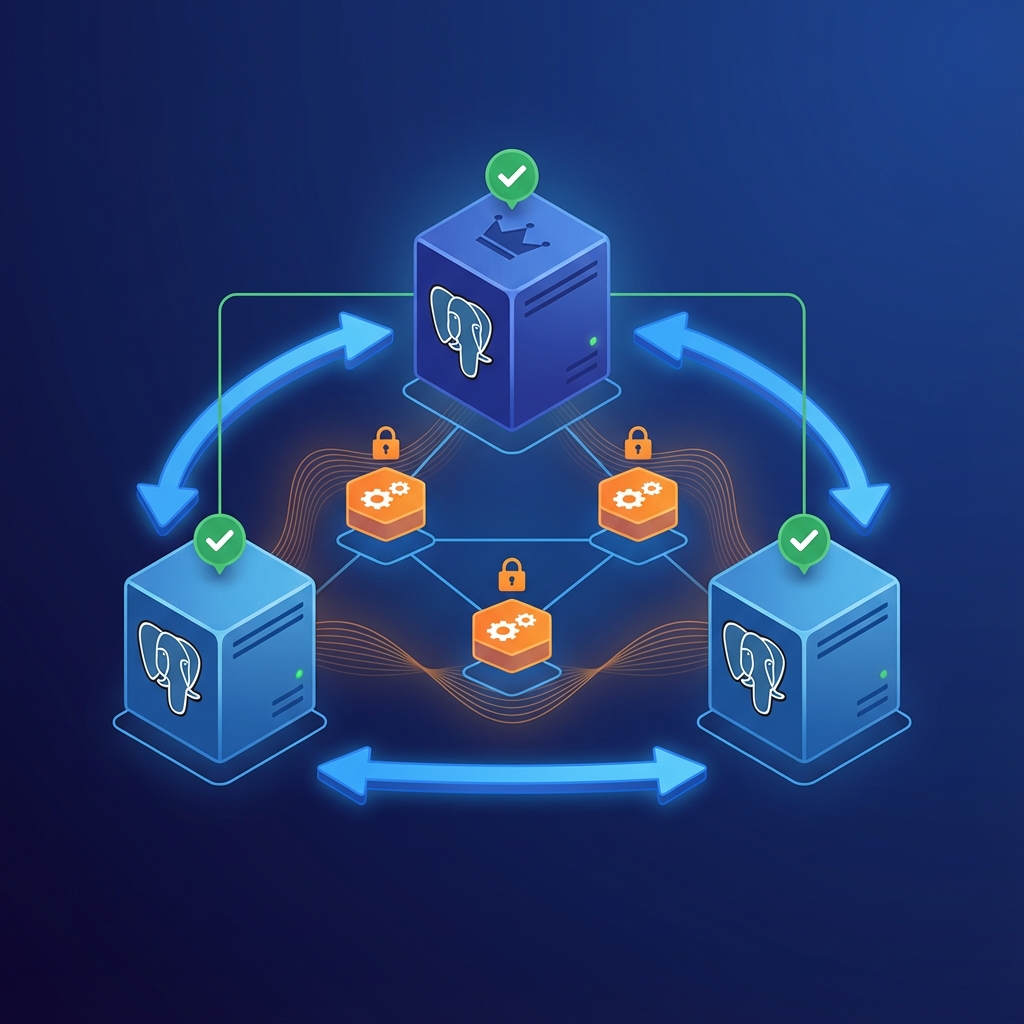
🧩 Les 3 Composants de l’Architecture
🐘 PostgreSQL + Patroni
Patroni est un template de haute disponibilité pour PostgreSQL développé par Zalando. Il gère :
- L’initialisation automatique du cluster
- La réplication streaming (synchrone ou asynchrone)
- La promotion d’un replica en primary (failover)
- Le switchover planifié (maintenance)
- La réinsertion d’un ancien primary comme replica
🗄️ etcd – Le Distributed Consensus Store
etcd est une base de données clé-valeur distribuée qui garantit la cohérence forte via l’algorithme Raft. Dans notre architecture :
- Il stocke le leader lock : quel nœud est Primary
- Il maintient la configuration du cluster
- Il fournit les health checks des nœuds
Quorum : Avec 3 nœuds etcd, on tolère la perte d’1 nœud. Avec 5, on tolère 2.
⚖️ HAProxy – Le Load Balancer
HAProxy route les connexions clients vers le bon nœud PostgreSQL :
- Port 5000 : Read-Write → Primary uniquement
- Port 5001 : Read-Only → Replicas (load balanced)
HAProxy utilise l’API REST de Patroni pour déterminer l’état de chaque nœud.
🔄 Failover Automatique : Comment ça Marche
Voici le scénario d’un failover automatique :
- T+0s : Le Primary tombe (crash, perte réseau)
- T+5s : etcd détecte que le Primary ne renouvelle plus son lease
- T+10s : Le lease expire, etcd libère le lock de leader
- T+11s : Les Replicas « candidatent » pour devenir Primary
- T+12s : Patroni choisit le replica le plus à jour (LSN le plus élevé)
- T+13s : Le replica promu acquiert le lock leader dans etcd
- T+15s : Les applications sont automatiquement reroutées via HAProxy
Temps de failover : ~15-30 secondes selon la configuration.
🔀 Réplication Synchrone vs Asynchrone
C’est un choix architectural fondamental :
Réplication Asynchrone (défaut)
Primary → Commit → ACK client → Réplication vers Replicas
- ✅ Meilleures performances (pas d’attente réseau)
- ❌ Risque de perte de données en cas de crash (transactions non répliquées)
- Adapté à : Applications tolérantes à une petite perte de données
Réplication Synchrone
Primary → Réplication vers Replica → Replica ACK → Commit → ACK client
- ✅ RPO = 0 : aucune perte de données possible
- ❌ Latence accrue (attente du replica)
- ❌ Si le replica synchrone tombe, le Primary est bloqué
- Adapté à : Banque, finance, données critiques
Patroni gère intelligemment le mode synchrone avec synchronous_mode: true.
🛠️ patronictl : L’Outil CLI Indispensable
Patroni fournit un outil en ligne de commande puissant :
# Voir l'état du cluster patronictl -c /etc/patroni/patroni.yml list # Résultat typique : + Cluster: postgres-cluster (7654321098765) ----+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +-----------+---------------+---------+---------+----+-----------+ | pg-node-1 | 192.168.1.10 | Leader | running | 5 | | | pg-node-2 | 192.168.1.11 | Replica | running | 5 | 0.0 | | pg-node-3 | 192.168.1.12 | Replica | running | 5 | 0.0 | +-----------+---------------+---------+---------+----+-----------+ # Switchover planifié (maintenance) patronictl switchover --master pg-node-1 --candidate pg-node-2 # Failover forcé (si le leader est vraiment mort) patronictl failover --candidate pg-node-2 # Réinitialiser un nœud patronictl reinit postgres-cluster pg-node-1
📊 Ports et Communications
| Port | Service | Description |
|---|---|---|
| 5432 | PostgreSQL | Connexion directe (non recommandé en HA) |
| 8008 | Patroni REST API | Health checks, état du cluster |
| 2379 | etcd client | Communication client → etcd |
| 2380 | etcd peer | Communication inter-nœuds etcd |
| 5000 | HAProxy | Read-Write (Primary only) |
| 5001 | HAProxy | Read-Only (Replicas) |
| 7000 | HAProxy Stats | Interface web de monitoring |
🏗️ Modes de Déploiement
Mode Colocalisé (Simple)
etcd et HAProxy sont installés sur les mêmes nœuds que PostgreSQL :
Node 1: PostgreSQL + Patroni + etcd + HAProxyNode 2: PostgreSQL + Patroni + etcd + HAProxyNode 3: PostgreSQL + Patroni + etcd + HAProxy
✅ Moins de machines, configuration simple
❌ etcd partage les ressources avec la DB
Mode Dédié
etcd et HAProxy sur des nœuds séparés :
DB Nodes: pg-1, pg-2, pg-3 (PostgreSQL + Patroni)etcd Nodes: etcd-1, etcd-2, etcd-3HAProxy Nodes: lb-1, lb-2 (avec keepalived)
✅ Isolation des ressources, scalabilité
❌ Plus de machines à gérer
🚀 Automatiser le Déploiement
Déployer cette architecture manuellement est un projet en soi :
- Installation et configuration etcd sur 3+ nœuds
- Configuration réseau et clustering
- Installation PostgreSQL depuis les dépôts officiels
- Configuration Patroni avec tous les paramètres
- Installation HAProxy avec backend dynamique
- Gestion des secrets (mots de passe réplication)
Notre rôle Ansible automatise toute cette complexité :
- ✅ PostgreSQL 17 avec Patroni 4.0.4
- ✅ etcd 3.5.17 en mode colocalisé ou dédié
- ✅ HAProxy avec health checks Patroni
- ✅ Mode synchrone configurable
- ✅ Debug mode pour le troubleshooting
- ✅ Documentation Day-1 et Day-2 complète
Prêt pour une base de données qui ne tombe jamais ? Découvrez notre rôle Ansible postgres_ha.
📖 Glossaire
- SPOF (Single Point of Failure) : Composant unique dont la panne entraîne l’arrêt complet du service
- Split-Brain : Situation catastrophique où deux nœuds se croient tous deux le Primary et acceptent des écritures
- Quorum : Nombre minimum de nœuds devant s’accorder pour prendre une décision (majorité)
- Failover : Basculement automatique vers un serveur de secours en cas de panne
- Switchover : Basculement planifié (maintenance) vers un autre nœud
- LSN (Log Sequence Number) : Position dans le journal de transactions PostgreSQL, utilisé pour déterminer quel replica est le plus à jour
- RPO (Recovery Point Objective) : Quantité maximale de données pouvant être perdues en cas de panne
- Raft : Algorithme de consensus distribué utilisé par etcd
Le prochain article portera sur la centralisation de l’authentification avec Keycloak en haute disponibilité. Restez connectés !